LLMのファインチューニングとは?:基本から応用まで徹底解説
- 2024.05.26
- Tuning
Fine-tuning(ファインチューニング)とは?
Fine-tuning(ファインチューニング)は、特定のタスクやドメインに合わせて、事前に訓練された大規模言語モデル(LLM)のパラメータを微調整するプロセスです。GPTなどの事前訓練済みの言語モデルは、幅広い言語知識を持っていますが、特定の領域における専門知識までカバーしているわけではありません。ファインチューニングを通じて、これらのモデルはドメイン固有のデータセットを用いてさらに学習を行い、目指すタスクやアプリケーションに対してより精度高く機能するようになります。
ファインチューニングのプロセスでは、モデルが特定のタスク固有の例に曝露されることで、そのドメインの繊細なニュアンスや特性をより深く捉えることが可能になります。(モデルが特定のタスク固有の例に曝露される”という表現は、機械学習やAIにおけるファインチューニングのプロセスを説明する際によく使われます。これは、既にある程度一般的な知識で訓練されたモデルに、さらに特定のタスクやドメインに関連するデータセットを用いて訓練を施し、モデルがその特定のタスクにおける細かなニュアンスやパターンを学習することを意味します。具体的には、例えば、一般的な言語理解のために訓練されたモデルに対して、医療分野の質問応答システムのタスクを学習させたい場合、医療関連の質問とその回答から成るデータセットを用いて追加の訓練を行います。この追加訓練により、モデルは医療分野特有の語彙や概念、質問の形式などを学習し、そのタスクにおいてより高いパフォーマンスを発揮できるようになります。この「曝露」という言葉は、モデルが特定の情報やデータに「さらされる」ことを指し、その過程でモデルがデータから学習し、知識を吸収していく様子を表現しています。要するに、モデルが特定のタスク固有の例に曝露されることで、そのタスクに最適化された知識と能力を身につけるというわけです。)
この手法によって、一般的な言語モデルと特化したモデルとの間の差を縮め、特定のドメインやアプリケーションでのLLMの潜在能力を最大限に引き出すことができます。ファインチューニングは、モデルを特定の用途に合わせてカスタマイズすることにより、より高いパフォーマンスと効果性を実現します。
Fine-tuning(ファインチューニング)が必要な理由とは?
カスタマイズ
- ドメイン特化のニーズ: 各ドメインやタスクには独自の言語パターンや専門用語が存在します。事前訓練済みのLLMは広範囲の知識を持っていますが、特定の領域における細かなニュアンスまではカバーしていないことが多いです。ファインチューニングを行うことで、これらの独自の側面を理解し、ドメイン特有のコンテンツ生成やタスク実行が可能になります。
- 応答の精度向上: 特定のタスクやアプリケーションに対して、より正確で文脈に合った応答を生成するためには、モデルがそのドメインのデータで追加訓練を受ける必要があります。これにより、モデルの応答の質が向上し、ユーザーのニーズにより適切に対応できるようになります。
データコンプライアンス
- 規制とプライバシー: 医療、金融、法律などの業界では、データの取り扱いに厳格な規制があります。ファインチューニングにより、企業はこれらの規制を遵守しつつ、独自のデータを用いてモデルを訓練することができます。これにより、機密情報の保護を強化しつつ、特定のニーズに合わせたモデルを開発できます。
データ不足の解決
- 限られたデータの活用: 特定のドメインやタスクに関連する大量のラベル付きデータを入手することは、しばしば困難でありコストもかかります。事前訓練済みのモデルをファインチューニングすることで、限られたデータでも高いパフォーマンスを達成することが可能です。これにより、データの少なさや不完全さの課題を克服し、ターゲットとするタスクにおけるモデルの有効性を向上させることができます。
ファインチューニングの種類(基礎編)
a. 特徴抽出 (Extract Features)
概要
特徴抽出 (Extract Features)、別名「再利用 (repurposing)」とは、LLMを特定のタスクに適用するための基本的な方法の一つです。このアプローチでは、事前訓練済みのLLMを固定された特徴抽出として使用します。
プロセス
事前に広範なデータで訓練されたモデルは、多岐にわたる重要な言語特徴を学習しています。これらの特徴は、新しい、特定のタスクに対して再利用することが可能です。この方法では、モデルの最終層だけがタスク固有のデータに基づいて訓練され、モデルの残りの部分は変更されません(凍結されたままです)。このアプローチは、LLMが獲得した豊かな情報を利用し、特定のタスクに適応させることで、コスト効率良く効果的にLLMをファインチューニングする方法を提供します。
b. フルファインチューニング(Full fine-tuning)
概要
フルファインチューニング(Full fine-tuning)は、特定の目的にLLMを調整するためのもう一つの基本的なアプローチです。特徴抽出 (Extract Features)とは異なり、この方法ではモデル全体がタスク固有のデータで訓練されます。
プロセス
フルファインチューニングでは、訓練プロセス中にモデルの全ての層が調整されます。これは、タスク固有のデータセットが大規模であり、事前訓練データと大きく異なる場合に特に有効です。モデル全体をタスク固有のデータで訓練することで、モデルはその特定のタスクに深く適応し、結果として優れたパフォーマンスを発揮する可能性があります。ただし、フルファインチューニングは特徴抽出 (Extract Features)よりも多くの計算リソースと時間を必要とします。
ファインチューニングの種類(応用編)
ファインチューニングにはいくつかの方法やテクニックがあり、これらはモデルのパラメータを特定の要件に合わせて調整するために使用されます。大まかに、これらの方法を2つのカテゴリに分類することができます:supervised fine-tuning とreinforcement learning from human feedback (RLHF)です。
a. Supervised fine-tuningとは?
この方法では、モデルはタスク固有のラベル付き教師データセットで訓練され、各入力データポイントは正しい答えやラベルと関連付けられます。モデルは、これらのラベルをできるだけ正確に予測するようにパラメータを調整する方法を学びます。このプロセスは、モデルが広範なデータセットでの事前訓練から得た既存の知識を、手元の特定のタスクに適用するように導きます。教師ありファインチューニングは、タスクのパフォーマンスを大幅に向上させることができ、LLMをカスタマイズするための効果的かつ効率的な方法となります。
教師ありファインチューニングの最も一般的なテクニックは以下の通りです:
- Basic hyperparameter tuning 基本的なハイパーパラメータチューニング 基本的なハイパーパラメータチューニングは、学習率、バッチサイズ、エポック数などのモデルハイパーパラメータを手動で調整するシンプルなアプローチです。目標は、モデルがデータから最も効果的に学習できるハイパーパラメータのセットを見つけることで、学習速度と過学習のリスクのトレードオフをバランスさせます。最適なハイパーパラメータは、特定のタスクでのモデルのパフォーマンスを大幅に向上させることができます。
- Transfer learning 転移学習 転移学習は、特にタスク固有のデータが限られている場合に有益な強力なテクニックです。このアプローチでは、広範な一般データセットで事前訓練されたモデルを出発点として使用します。その後、モデルをタスク固有のデータでファインチューニングし、新しいタスクに既存の知識を適応させます。このプロセスは、必要なデータ量と訓練時間を大幅に削減し、しばしばゼロからモデルを訓練する場合と比較して優れたパフォーマンスをもたらします。
- Multi-task learning マルチタスク学習 マルチタスク学習では、モデルを複数の関連するタスクで同時にファインチューニングします。このアイデアは、これらのタスク間の共通点と相違点を活用して、モデルのパフォーマンスを向上させることです。複数のタスクを同時に実行する方法を学ぶことで、モデルはデータに対するより堅牢で一般化された理解を開発できます。このアプローチは、特に実行するタスクが密接に関連している場合や、個々のタスクに対して限られたデータがある場合に、パフォーマンスを向上させます。マルチタスク学習には、各タスクのラベル付きデータセットが必要であり、教師ありファインチューニングの固有の要素となります。
- Few-shot learning 少数ショット学習 少数ショット学習は、モデルが少量のタスク固有のデータで新しいタスクに適応できるようにする方法です。このアイデアは、事前訓練から得た広範な知識を活用して、新しいタスクのわずかな例から効果的に学習することです。このアプローチは、タスク固有のラベル付きデータが少ないか高価な場合に有益です。このテクニックでは、モデルに新しいタスクを学ぶための数例(ショット)が推論時に与えられ、プロンプト内で直接コンテキストと例を提供することでモデルの予測を導きます。少数ショット学習は、タスク固有のデータに人間のフィードバックが含まれている場合、reinforcement learning from human feedback(RLHF)アプローチに統合することもできます。
- タスク固有のファインチューニング
この方法では、モデルがターゲットとするタスクのニュアンスと要件にパラメータを適応させ、その特定のドメインにおけるパフォーマンスと関連性を向上させます。タスク固有のファインチューニングは、モデルのパフォーマンスを単一の明確に定義されたタスクに最適化したい場合に特に価値があります。これにより、モデルはタスク固有のコンテンツを精度と正確さで生成することに優れています。タスク固有のファインチューニングは、転移学習と密接に関連していますが、転移学習はモデルによって学習された一般的な特徴を活用することについてであり、タスク固有のファインチューニングは新しいタスクの特定の要件にモデルを適応させることについてです。
b. reinforcement learning from human feedbackとは?(RLHF)
reinforcement learning from human feedback(RLHF)は、人間のフィードバックとの相互作用を通じて言語モデルを訓練する革新的なアプローチです。学習プロセスに人間のフィードバックを組み込むことで、RLHFは言語モデルを連続的に強化し、より正確で文脈に適した応答を生成するように促します。
このアプローチは、人間の評価者の専門知識を活用するだけでなく、実世界のフィードバックに基づいてモデルが適応し進化することを可能にし、最終的により効果的で洗練された能力につながります。
- Reward modeling 報酬モデリング
この手法では、モデルが複数の可能性のある出力や行動を生成し、人間の評価者がこれらの出力を品質基準でランク付けまたは評価します。モデルは、これらの人間提供の報酬を予測し、予想される報酬を最大化するようにその振る舞いを調整します。報酬モデリングは、学習プロセスに人間の判断を組み込む実用的な方法を提供し、単純な関数では定義しにくい複雑なタスクを学習することを可能にします。この方法により、モデルは人間から提供されるインセンティブに基づいて学習し適応し、最終的にその能力を向上させます。 - Proximal policy optimization (PPO)近接方策最適化
Proximal policy optimization (PPO)は、期待される報酬を最大化するために言語モデルの方策を更新する反復的なアルゴリズムです。PPOの核心は、前の方策から過度に逸脱しないようにしつつ、方策を改善する行動を取ることです。このバランスは、有害な大規模更新を防ぎつつ有益な小規模更新を許可する方策更新に制約を導入することで達成されます。この制約は、制約として機能するクリップされた確率比を持つ代理目的関数を導入することで強制されます。このアプローチは、他の強化学習手法と比較してアルゴリズムをより安定かつ効率的にします。 - Comparative ranking 比較ランキング
Comparative ranking 比較ランキングはReward modeling 報酬モデリングに類似していますが、比較ランキングではモデルが人間の評価者によって提供された複数の出力の相対的なランキングから学習し、異なる出力間の比較に重点を置きます。このアプローチでは、モデルが複数の出力や行動を生成し、人間の評価者がこれらを品質や適切性に基づいてランク付けします。モデルは、評価者によってより高く評価された出力を生成するように振る舞いを調整します。複数の出力を比較してランク付けすることで、比較ランキングはモデルにより微妙で相対的なフィードバックを提供し、タスクの微妙な違いをより良く理解するのに役立ち、結果を改善します。 - Preference learning 優先度学習
優先度学習は、状態、行動、または軌道間の好みの形で人間のフィードバックから学習するモデルを訓練することに焦点を当てています。このアプローチでは、モデルが複数の出力を生成し、人間の評価者が出力ペア間の好みを示します。モデルは、人間の評価者の好みに合致する出力を生成するように振る舞いを調整します。この方法は、出力品質を数値的な報酬で定量化することが難しいが、2つの出力間の好みを表現する方が簡単な場合に有用です。好み学習により、モデルは微妙な人間の判断に基づいて複雑なタスクを学習でき、実生活のアプリケーションでモデルをファインチューニングするための効果的なテクニックとなります。 - Parameter efficient fine-tuning (PEFT)パラメータ効率的なファインチューニング
Parameter efficient fine-tuning (PEFT)は、特定の下流タスクで事前訓練されたLLMのパフォーマンスを向上させるために使用される手法で、訓練可能なパラメータの数を最小限に抑えます。このアプローチは、ファインチューニング中にモデルパラメータの一部のみを更新することで、より効率的な方法を提供します。PEFTは、LLMのパラメータの小さなサブセットのみを選択的に修正し、通常は新しいレイヤーを追加したり、既存のものをタスク固有の方法で変更したりします。このアプローチは、計算とストレージの要件を大幅に削減しながら、フルファインチューニングと比較して同等のパフォーマンスを維持します。
ファインチューニングのプロセスと適切な手法
a. データの準備
データの準備には、特定のタスクに適したデータセットを整備・前処理する作業が含まれます。これには、データのクリーニング、欠損値の処理、モデルの入力要件に合わせたテキストのフォーマット調整などが必要になる場合があります。
また、データ拡張技術を用いてトレーニングデータセットを増やし、モデルの堅牢性を高めることも可能です。適切なデータ準備は、モデルが効率的に学習し、一般化する能力に直接影響を与え、タスク特有の出力の精度とパフォーマンスを向上させるため、不可欠です。
b. 適切な事前訓練モデルの選択
ターゲットタスクやドメインの具体的な要件に合致する事前訓練モデルを選択することが重要です。事前訓練モデルのアーキテクチャ、入出力仕様、レイヤーを理解することは、ファインチューニングワークフローにおいてスムーズな統合を実現するために欠かせません。
モデルのサイズ、トレーニングデータ、関連するタスクでのパフォーマンスなどの要素を考慮して選択を行います。目標タスクの特性に密接にマッチする事前訓練モデルを選ぶことで、ファインチューニングプロセスを効率化し、意図したアプリケーションでの適応性と効果を最大限に引き出すことができます。
c. ファインチューニングにおける適切なパラメータ(pre-trained model)の特定
ファインチューニングパラメータの設定は、プロセスにおいて最適なパフォーマンスを達成するために重要です。学習率、トレーニングエポック数、バッチサイズなどのパラメータが、新しいタスク固有のデータへのモデルの適応方法を決定します。
また、特定のレイヤー(通常は初期のもの)を凍結させる一方で、最終レイヤーのトレーニングを行うことは、過学習を防ぐための一般的な手法です。初期レイヤーを凍結させることで、モデルは事前訓練中に得た一般的な知識を維持しつつ、最終レイヤーが新しいタスクに特化して適応することを可能にします。このアプローチは、モデルの一般化能力を維持しつつ、タスク特有の特徴を効果的に学習するバランスをとるのに役立ちます。
d. 検証
検証では、ファインチューニングされたモデルのパフォーマンスを検証セットを使用して評価します。精度、損失、適合率、再現率などの指標を監視することで、モデルの有効性や一般化能力に関する洞察を得ることができます。
これらの指標を評価することで、ファインチューニングされたモデルがタスク特有のデータでどれだけうまく機能しているかを判断し、改善の余地を見つけ出すことができます。この検証プロセスにより、ファインチューニングパラメータやモデルアーキテクチャを洗練させ、意図したアプリケーションに対して正確な出力を生成する最適化されたモデルに導くことができます。
e. モデルの反復
モデルの反復により、評価結果に基づいてモデルを改善できます。モデルのパフォーマンスを評価した後、学習率やバッチサイズ、レイヤーの凍結範囲など、ファインチューニングパラメータの調整を行い、モデルの有効性を高めることができます。
さらに、正則化技術の採用やモデルアーキテクチャの調整など、異なる戦略を探求することで、モデルのパフォーマンスを反復的に向上させることが可能です。これにより、エンジニアは目的に合わせてモデルをファインチューニングし、望ましいパフォーマンスレベルを達成するまでその能力を徐々に洗練させることができます。
f. モデルの展開
モデルの展開は、開発から実際のアプリケーションへの移行を示し、特定の環境へのファインチューニングされたモデルの統合を含みます。このプロセスには、展開環境のハードウェアおよびソフトウェア要件、既存のシステムやアプリケーションへのモデル統合に関する考慮事項が含まれます。
また、スケーラビリティ、リアルタイム性能、セキュリティ対策などの側面も、シームレスで信頼性の高い展開を保証するために対処する必要があります。ファインチューニングされたモデルを特定の環境に成功裏に展開することで、その強化された能力を実世界の課題に対処するために活用できます。
ファインチューニングの実用化できる領域
事前訓練済みモデルのファインチューニングは、特定のタスクに大規模モデルの力を活用する効率的な方法であり、ゼロからモデルを訓練する必要がないという利点があります。ファインチューニングされた大言語モデル(LLM)が顕著な利益を提供する主な使用例を以下に紹介します。
a. 感情分析
企業データ、特定のドメイン、またはユニークなタスクにモデルをファインチューニングすることで、テキストコンテンツに表現された感情を正確に分析・理解することが可能になります。これにより、顧客フィードバック、ソーシャルメディアの投稿、製品レビューから貴重な洞察を得ることができ、意思決定プロセス、マーケティング戦略、製品開発の取り組みに役立ちます。
例えば、感情分析は企業がトレンドを特定し、顧客満足度を測定し、改善の余地を見つけ出すのに役立ちます。ソーシャルメディアでは、ファインチューニングされたモデルを使用してブランド、製品、またはサービスに対する公衆の感情を追跡し、積極的な評判管理と顧客とのターゲットとなるエンゲージメントを可能にします。全体として、ファインチューニングされた大言語モデルは、顧客の感情に関する貴重な洞察を提供できる強力な感情分析ツールです。
b. チャットボット
ファインチューニングにより、チャットボットはより文脈に適した魅力的な会話を生成し、顧客とのやりとりを改善し、顧客サービス、医療、電子商取引、金融など様々な業界でパーソナライズされたアシスタンスを提供します。例えば、医療分野では、チャットボットが詳細な医療に関する問い合わせに答え、サポートを提供し、患者ケアと医療情報へのアクセス性を向上させることができます。
電子商取引では、ファインチューニングされたチャットボットが顧客の製品に関する問い合わせに対応し、好みに基づいてアイテムを推薦し、シームレスな取引を促進します。金融業界では、チャットボットがパーソナライズされた金融アドバイスを提供し、アカウント管理をサポートし、高い精度と関連性で顧客の問い合わせに対応できます。全体として、チャットボットアプリケーションのための言語モデルのファインチューニングは、その会話能力を向上させ、幅広い業界で貴重な資産となります。
c. 要約
ファインチューニングされたモデルは、長いドキュメント、記事、または会話の簡潔で情報豊かな要約を自動生成し、効率的な情報検索と知識管理を促進します。この能力は、大量のデータを分析して重要な洞察を抽出する必要がある専門家にとって非常に貴重です。
学術研究では、ファインチューニングされた要約モデルが広範な研究論文を要約し、学者が重要な発見と洞察をより迅速に把握できるようにします。企業環境では、ファインチューニングされた要約モデルが長いレポート、メール、ビジネスドキュメントを要約し、効率的な意思決定と知識の理解を促進します。全体として、要約のためのファインチューニングされた言語モデルの適用は、情報のアクセシビリティと理解を向上させ、様々な領域で貴重なツールとなります。
ファインチューニングされたモデルは、様々な使用例で最適化された結果を提供し、ユニークなビジネスソリューションのためのLLMの能力を高めるファインチューニングの多様性と影響を示しています。
ファインチューニングを採用しない方が良い場合
大規模言語モデル(LLM)は、膨大なテキストやコードのデータセットで事前に訓練されており、テキスト生成、翻訳、質問応答など、幅広いタスクを学習する能力を持っています。しかし、LLMのファインチューニングが常に必要であったり、望ましいわけではありません。
以下は、LLMのファインチューニングを使用しない方が良いケースの例です:
- モデルがファインチューニングで利用できない場合
一部のLLMは、ファインチューニングを許可しないアプリケーションプログラミングインターフェース(API)を通じてのみ利用可能です。※大規模言語モデル(LLM)が提供されている状況を指しています。この場合、LLMはAPI経由で外部の開発者やユーザーにサービスとして提供されていますが、そのAPIはユーザーがモデル自体を直接ファインチューニングする、つまりモデルのパラメータを特定のタスクやデータセットに合わせて調整することを許可していません。簡単に言うと、このLLMを使いたい場合、ユーザーはAPIを通じてモデルにアクセスできますが、モデルが事前に学習した内容をそのまま利用するしかありません。ユーザーは自分の特定のニーズやデータセットに合わせてモデルをカスタマイズするために、モデルの内部パラメータを調整することができないという意味です。これは、API提供者が、モデルの安定性やセキュリティ、または商業的な理由からファインチューニングを制限している場合によく見られます。 - ファインチューニングに十分なデータがない場合
LLMのファインチューニングには、ラベル付けされた大量のデータセットが必要です。十分なデータがない場合、ファインチューニングで良い結果を得ることはできないかもしれません。 - データが常に変化する場合
LLMが使用されるデータが常に変化している場合、ファインチューニングは追いつけない可能性があります。これは、特に機械的な翻訳のようなタスクは、ソース言語の語彙や文法が時間とともに変化する可能性があります。 - アプリケーションが動的で文脈に敏感な場合
あるケースでは、LLMの出力がユーザーや状況の特定の文脈に合わせて調整される必要があります。例えば、顧客サービスアプリケーションで使用されるチャットボットは、顧客の意図を理解し、それに応じて反応する能力が必要です。このタイプのアプリケーションのためにLLMをファインチューニングすることは困難であり、チャットボットが使用されるさまざまな文脈を捉えた大量のラベル付きデータセットが必要になります。
これらのケースでは、以下のような異なるアプローチを検討することをお勧めします:
- より小さく、複雑でないモデルを使用する
小さなモデルは、訓練やファインチューニングにかかる計算コストが少なく、一部のタスクには十分な可能性があります。 - Transfer learning approach(転移学習)を使用する
転移学習は、異なるタスクで訓練されたモデルを使用して新しいタスクのモデルを初期化する技術です。これは、新しいタスクのモデルを訓練するためのより効率的な方法であり、モデルがより速く学習するのに役立ちます。 - In-context learning(文脈学習)やRAG(Retrieval-Augmented Generation:検索拡張生成)を使用する
文脈学習や検索拡張生成は、推論時にLLMに文脈を提供する技術です。LLMが特定のタスクや質問に対する回答を生成する際に、より正確で関連性の高い結果を得るために、追加の情報や背景をモデルに与える手法のことを指します。この技術の目的は、モデルが単に一般的な知識に基づいて推論するのではなく、与えられた文脈や状況に応じて特定の回答を生成できるようにすることです。例えば、ある特定のトピックに関する質問に対してLLMを使用して回答を生成する場合、そのトピックに関連するキーワードや事前情報を文脈としてモデルに提供することで、モデルはよりトピックに適した、具体的で正確な回答を生成することができます。これにより、モデルの出力がより具体的でユーザーのニーズに合致するようになります。このアプローチは、特に複雑な質問応答システム、パーソナライズされたチャットボット、または特定の文脈や状況に基づく情報提供が必要なアプリケーションで有効です。文脈を提供することで、LLMは与えられた情報を基により深いレベルでの理解と推論を行い、結果としてユーザーにとってより価値の高い回答や情報を提供することが可能になります。
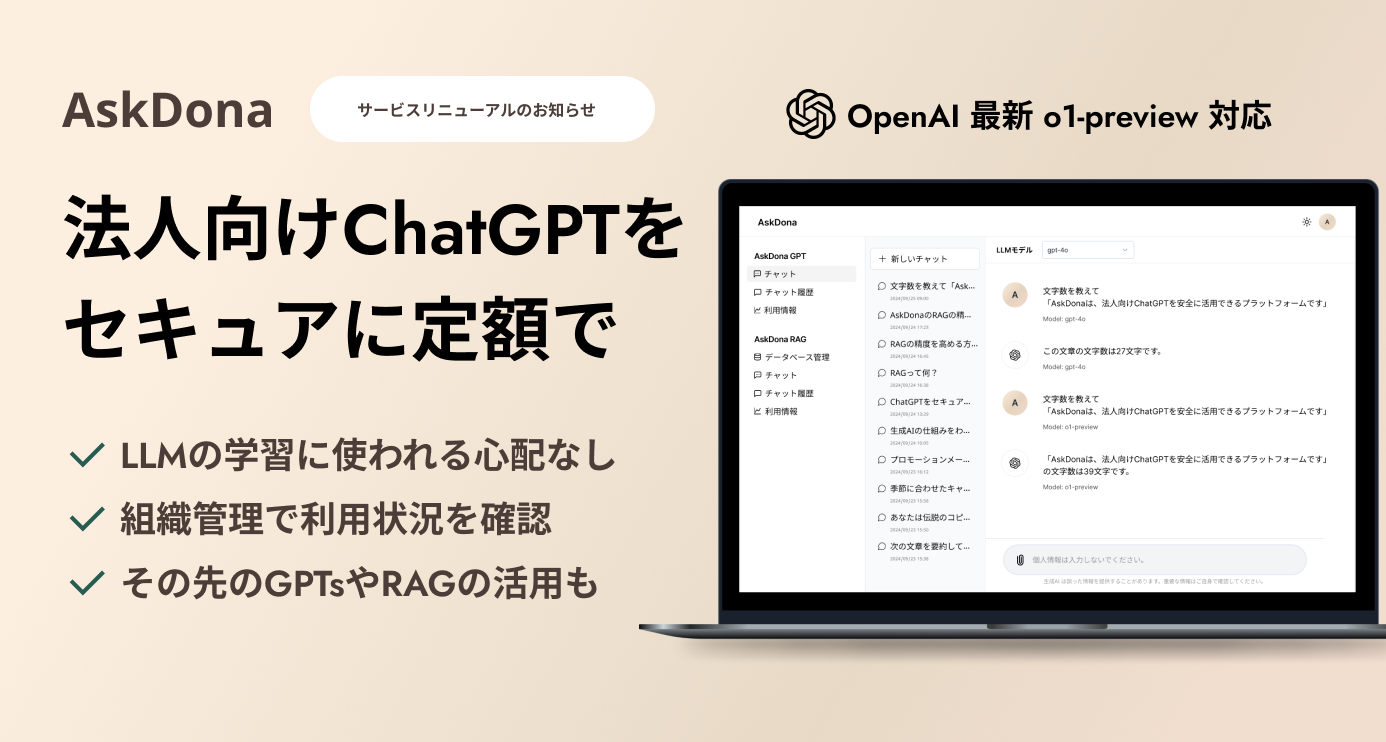
ファインチューニングと検索拡張生成(RAG)は、大規模言語モデル(LLM)の応用範囲を広げるための二つの異なるアプローチです。これらの手法はそれぞれ独自の利点を持ち、特定のシナリオや要件に応じて適切な選択を行うことが重要です。ファインチューニングはモデル自体のパラメータを直接調整して特定のタスクに合わせるのに対し、RAGは外部の情報源からの情報を検索し、その情報を基にテキスト生成を行うことで、モデルの出力を向上させます。
ファインチューニングは、特にラベル付きデータが豊富に存在し、モデルを特定のタスクやドメインに細かく調整したい場合に有効です。この手法により、モデルはタスク特有の微妙なニュアンスを学習し、より精度高くターゲットに合った出力を生成することができます。
一方、RAGは、既存の知識ベースや情報源を活用して、モデルが新しい情報に基づいた回答を生成する能力を高めたい場合に適しています。このアプローチは、情報が日々更新される分野や、特定の質問に対して即座に正確な回答を提供する必要があるシナリオで特に有効です。
適切な手法の選択は、利用可能なデータの量と質、タスクの性質、アプリケーションの動的な要件など、プロジェクトの具体的な条件に基づいて行うべきです。いずれの手法も、LLMを特定の用途に合わせて最適化し、その潜在能力を最大限に引き出すための強力なツールです。最終的に、ファインチューニングとRAGの両方を理解し、それぞれの長所と短所を考慮して、目的に最も合ったアプローチを選択することが、成功への鍵となります。
GFLOPS -AskDona
-
前の記事

今さら聞けないChatGPTって何?ChatGPTについてわかりやすく解説 2024.05.25
-
次の記事
RAGの一部に使われる、文脈内学習(In-Context Learning)とは? 2024.05.27