RAGの仕組みをわかりやすく解説、なぜRAGがビジネスに特化したLLMとして注目されているのか?
- 2024.05.25
- RAG
RAG ”ラグ”(Retrieval-Augmented Generation、検索拡張生成)は、大規模言語モデル(LLM)によるテキスト生成に、外部情報の検索を組み合わせることで、回答精度を向上させる技術のことです。「検索拡張生成」と訳され、外部情報の検索を組み合わせることで、大規模言語モデルの出力結果を簡単に最新の情報に更新できるようになる効果や、出力結果の根拠が明確になり、事実に基づかない情報を生成する現象(ハルシネーション)を抑制する効果などが期待されています。
RAGが解決する課題とは?
RAG(Retrieval-Augmented Generation、検索拡張生成)は、大規模言語モデル(LLM)によるテキスト生成に外部情報の検索を組み合わせることで、以下のような課題を解決することが期待されています。
- 回答精度の向上: RAGは、LLMが生成する回答に外部情報を組み合わせることにより、より正確で信頼性の高い情報に基づいた回答を提供することができます。これにより、LLMのみに依存した場合に発生する可能性のある誤った情報や不正確な回答を減らすことができます。
- 最新の情報へのアクセス: LLMはトレーニングされた時点のデータに基づいて回答を生成するため、最新の情報を反映した回答を提供することが困難です。RAGにより、外部の最新情報をリアルタイムで検索し、それを反映した回答を生成することが可能になります。
- ハルシネーションの抑制: 大規模言語モデルは、事実に基づかない情報を生成することがあります(これをハルシネーションと言います)。RAGは、外部情報を検索して回答に組み込むことにより、根拠のある情報に基づいた回答を提供し、ハルシネーションを抑制する効果が期待されます。
- 専門的または固有の情報への対応: 特定の専門分野や企業固有の情報に対する質問に対して、LLMだけでは適切な回答を生成することが難しい場合があります。RAGを使用することで、特定のデータベースや文書から関連情報を検索し、その情報を基に回答を生成することができるため、より専門的かつ固有の情報に基づいた回答を提供することが可能になります。
これらの課題解決により、RAGは、顧客サービス、知識管理、教育、研究など、さまざまな分野での応用が期待されています。
RAGのユースケースとは?
- 質問応答チャットボット: LLM(大規模言語モデル)をチャットボットに組み込むことで、企業の文書やナレッジベースからより正確な回答を自動的に導き出すことができます。このチャットボットは、顧客サポートを自動化し、ウェブサイトの新規見込み顧客に対して迅速に質問に応答たり、問題を解決したりすることができます。
- 検索拡張: LLMを検索エンジンに組み込むことで、LLMが生成した回答を検索結果に追加し、情報検索の質問に対してよりよい回答を提供したり、ユーザーが仕事を進めるために必要な情報を見つけやすくしたりすることができます。
- ナレッジベース — データへの質問: 企業データをLLMのコンテキストとして使用し、従業員が簡単に質問に答えられるようにします。これには、福利厚生やポリシーに関連する人事・労務・総務の質問や、セキュリティおよびコンプライアンスに関する質問が含まれます。
RAGを利用するメリットとは?
- 最新かつ正確な回答の提供:
- RAGは、LLMの回答が静的で古いトレーニングデータにのみ基づくことがないようにします。外部データソースを使用して最新の情報に基づいた回答を提供することで、より正確なインサイトと情報をユーザーに提供できます。
- 不正確な回答やハルシネーションの削減:
- LLMの出力を関連する外部知識に基づけることで、間違った情報や作り話に基づいた回答のリスクを軽減します。出力には元のソースへの引用を含めることができ、これにより人間による検証が可能になります。
- ドメイン固有の関連性のある回答の提供:
- 組織の独自のデータやドメイン固有のデータに合わせて、文脈に応じた関連性のある回答を提供できます。これにより、特定の分野や業界に特化した精度の高い回答が可能になります。
- 効率的かつコスト効果的:
- ドメイン固有のデータでLLMをカスタマイズする他のアプローチと比較して、RAGはシンプルでコスト効果が高いです。新しいデータでモデルを頻繁に更新する必要がある場合に特に有益です。
- 情報アクセスの改善:
- 質問応答システム、ナレッジベース、カスタマーサポートなどでの情報アクセスを改善し、ユーザーが必要とする情報を迅速かつ簡単に見つけることができるようにします。
RAG VS ファインチューニングどちらがいいの?
RAG(Retrieval-Augmented Generation、検索拡張生成)とモデルのファインチューニングは、大規模言語モデル(LLM)のカスタマイズにおいて異なるアプローチです。どちらの方法もそれぞれの利点があり、使用するシナリオに応じて適当に選択されるべきです。また、これらのアプローチは相互排他的ではなく、組み合わせて使用することで、それぞれの強みを活かすことができます。
RAG(検索拡張生成)の使用シナリオ
RAGは、特定の情報を提供する必要があるが、その情報が頻繁に更新されるか、または非常に専門的な知識が必要な場合に特に有効です。例えば、最新のニュースイベントに関する質問に答えたり、特定の専門分野における深い知識が必要な質問に対応したりする場合です。RAGは外部のデータソースを活用して、LLMが生成する応答の質と関連性を高めます。
モデルのファインチューニング使用シナリオ
ファインチューニングは、LLMの振る舞いを特定のタスクやドメインに合わせて調整したい場合に適しています。例えば、特定の業界用語を理解させたり、特定の形式での応答を生成させたりしたい場合です。ファインチューニングを通じて、モデルは特定のデータセットに基づいて追加のトレーニングを受け、その結果として振る舞いが変化します。
LLMカスタマイズのためのアーキテクチャパターン
- プロンプトエンジニアリング: LLMに特定のフォーマットや内容で応答させるために、入力プロンプトの工夫を行います。この方法は、特に追加のトレーニングを行わずに、既存のLLMの応答を最適化したい場合に有効です。
- RAG: 外部の情報源から最新または関連性の高い情報を取得し、LLMの応答生成に組み込むことで、応答の質を向上させます。これは、情報が頻繁に更新される場合や、特定の専門知識が必要な場合に特に有効です。
- ファインチューニング: 特定のデータセットを使用してLLMを追加でトレーニングし、その振る舞いを特定のタスクやドメインに合わせて調整します。これは、モデルに特定の専門知識や振る舞いを持たせたい場合に適しています。
- プレトレーニング: 新たにLLMをゼロからトレーニングするか、大規模な再トレーニングを行って、全く新しいモデルを作成します。これは、非常に特殊な要件がある場合や、既存のモデルでは対応できない新しいタスクに取り組みたい場合に考えられます。
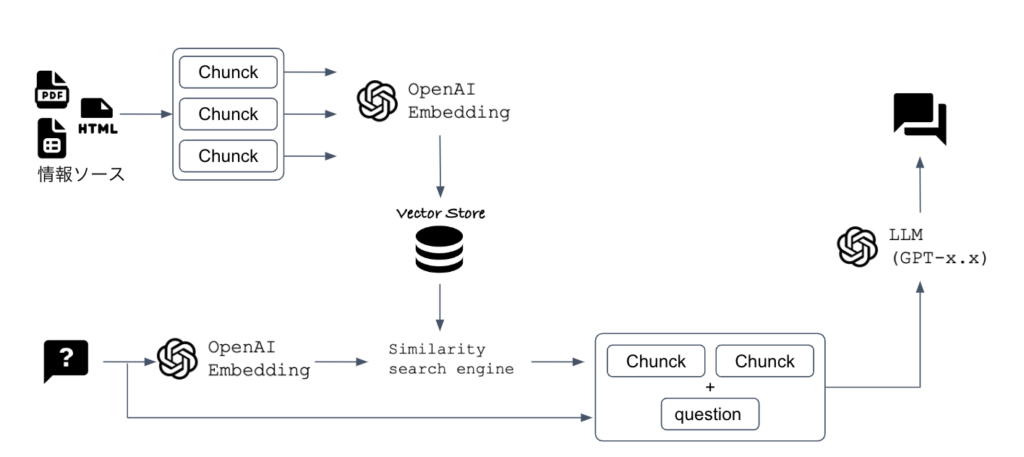
RAGの仕組みとは?
RAG(Retrieval-Augmented Generation、検索拡張生成)は、大規模言語モデル(LLM)を活用したテキスト生成において、特定の情報源への検索を組み合わせることで、生成される内容の正確性と関連性を高める技術です。RAGの仕組みは以下のステップで構成されます。
ステップ1: データの準備
まず、使用する情報源(例えば、ウェブページ、データベース、ドキュメントなど)からデータを収集し、必要に応じて前処理を行います。このプロセスには、個人情報の取り扱いや、データを適切なサイズに分割(チャンキング)する作業が含まれることがあります。
ステップ2: 関連データのインデックス化
収集したデータからドキュメントの埋め込み(ベクトル表現)を生成し、それらをベクトル検索インデックスに格納します。このインデックスは、後のステップでの高速な検索を可能にします。
ステップ3: 関連データの取得
ユーザーからのクエリを受け取った際に、ステップ2で作成したインデックスを使用して、そのクエリに関連するデータを検索します。この検索プロセスにより、クエリに最も関連性の高い情報の断片(スニペット)が特定されます。
ステップ4: LLMを用いたテキスト生成
関連する情報を特定したら、その情報をLLMのプロンプトの一部として追加します。そして、LLMにより、この追加されたコンテキスト情報を考慮した上で、最終的なテキスト(応答、記事、レポートなど)が生成されます。
ステップ5: アプリケーションへの統合
生成されたテキストは、最終的にQ&Aシステム、チャットボット、コンテンツ作成ツールなど、様々なアプリケーションに組み込まれ、ユーザーに提供されます。
GPT(Generative Pre-trained Transformer):
- GPTは、OpenAIによって開発された自然言語生成(NLG)のためのモデルです。
- 事前に大量のテキストデータでトレーニングされ、その知識をもとに新しいテキストを生成します。
- GPTは自己完結型で、トレーニングデータに含まれる情報を基に回答を生成しますが、リアルタイムで外部情報を取り込むことはできません。
- 一般的な質問に対して広範な知識を持つ回答を提供できますが、特定の最新情報や特定のドメインに特化した情報を含む回答には限界があります。
RAG(Retrieval-Augmented Generation):
- RAGは、GPTなどの生成モデルに外部からの情報検索機能を組み合わせたアプローチです。
- ユーザーのクエリに基づき、特定の情報源から最新または関連性の高い情報を検索し、その情報を基にテキストを生成します。
- RAGは、特定のドメインに特化した情報や最新情報を反映した回答を提供することができ、GPT単体では不可能なリアルタイム情報の取り込みが可能です。
- 特に、最新のデータや特定の専門領域の深い知識が必要な場合に有効です。
GPTとRAGの区別:
- GPTは、トレーニングされたデータに基づいて独立してテキストを生成します。これは一般的な質問に対して強力な回答を提供できますが、トレーニングデータの範囲外の情報を提供することはできません。
- RAGは、GPTなどの生成モデルに情報検索のステップを追加することで、生成されるテキストの質と関連性を高めます。これにより、特定のクエリに対して最新またはより正確な情報を含む回答を提供することが可能になります。
簡単に言うと、GPTは既に知っている情報を基にテキストを生成しますが、RAGは新しい情報をリアルタイムで取り込みながらテキストを生成することができる点が大きな違いです。
RAGを導入する際に留意しておきたい点
1. システムの複雑性が増す
- RAGシステムは、検索コンポーネントと生成コンポーネントの両方を組み合わせるため、単一の生成モデルよりも設計と実装が複雑になります。これにより、開発とメンテナンスのコストが増加する可能性があります。
2. パフォーマンスへの影響
- リアルタイムでの情報検索を行うため、応答時間が長くなることがあります。特に、大規模なデータベースを扱う場合や、高度な検索クエリを実行する場合、パフォーマンスに影響を及ぼす可能性があります。
3. 情報の正確性と信頼性
- RAGは検索された情報を基にテキストを生成するため、検索される情報源の正確性と信頼性が結果に直接影響します。情報源が最新でない場合や誤った情報を含む場合、生成されるテキストの質に影響を及ぼす可能性があります。
4. 情報源の選定と管理
- 関連性の高い情報を提供するためには、適切な情報源の選定が必要です。また、これらの情報源を常に最新の状態に保つための管理が必要になります。このプロセスは時間とリソースを要求されることがあります。
5. 倫理的およびプライバシーの懸念
- ユーザーからのクエリに基づいて外部データを検索する際、個人情報や機密情報が含まれる可能性があります。これらの情報の取り扱いには、高い倫理観とプライバシー保護の対策が必要になります。
6. コスト
- RAGシステムを運用するためには、検索エンジンやデータベース、生成モデルなどのインフラストラクチャに投資する必要があります。特に、大規模なデータセットを扱う場合、このコストは顕著になる可能性があります。
企業が生成AIを導入するならRAGの活用を検討すべき理由
1. 最新かつ正確な情報の提供
RAGは外部の情報源から最新のデータを検索してテキスト生成に組み込むため、企業は顧客に対して常に最新かつ正確な情報を提供することができます。これにより、顧客の信頼を得ることができ、ブランドの信頼性を高めることができます。
2. カスタマーサポートの向上
RAGを活用することで、カスタマーサポートにおける問い合わせへの迅速かつ正確な回答が可能になります。これは、顧客満足度の向上に直結し、リピート率や顧客ロイヤルティの向上に寄与します。
3. 効率的なコンテンツ生成
企業が提供するサービスや製品に関連するコンテンツを効率的に生成できるため、マーケティングや情報提供の効率が向上します。RAGによる高品質なコンテンツの生成は、SEO(検索エンジン最適化)の向上にも役立ちます。
4. ナレッジベースの強化
企業内のナレッジベースやドキュメント管理システムにRAGを組み込むことで、従業員が必要とする情報を迅速に検索し、アクセスすることができます。これにより、業務の効率性が向上し、従業員の生産性を高めることができます。
5. 競争力の向上
最新のAI技術を活用することで、企業は競合他社との差別化を図ることができます。RAGを活用したサービスや製品は、顧客に新たな価値を提供し、市場における競争力を高めることができます。
6. 柔軟性とスケーラビリティ
RAGは様々な業界や用途に応じてカスタマイズ可能であり、企業の成長に合わせてスケールアップすることができます。これにより、企業は将来にわたって技術的な柔軟性とスケーラビリティを確保することができます。
まとめ
RAG(Retrieval-Augmented Generation、検索拡張生成)は、企業が直面する多様な情報関連の課題に対して革新的な解決策を提供します。最新かつ正確な情報提供の必要性、顧客満足度の向上、効率的なコンテンツ生成、そして競争力の強化という点で、RAGは企業にとって価値ある資産となり得ます。これらの利点を活かし、企業が今後の成長と発展のためにRAGを積極的に採用し、活用していくことを心よりお勧めします。最新技術を取り入れ、常に一歩先を行く企業であり続けることが、未来への成功への鍵となるでしょう。
Generated by GFLOPS -AskDona
-
前の記事
記事がありません
-
次の記事

今さら聞けないChatGPTって何?ChatGPTについてわかりやすく解説 2024.05.25