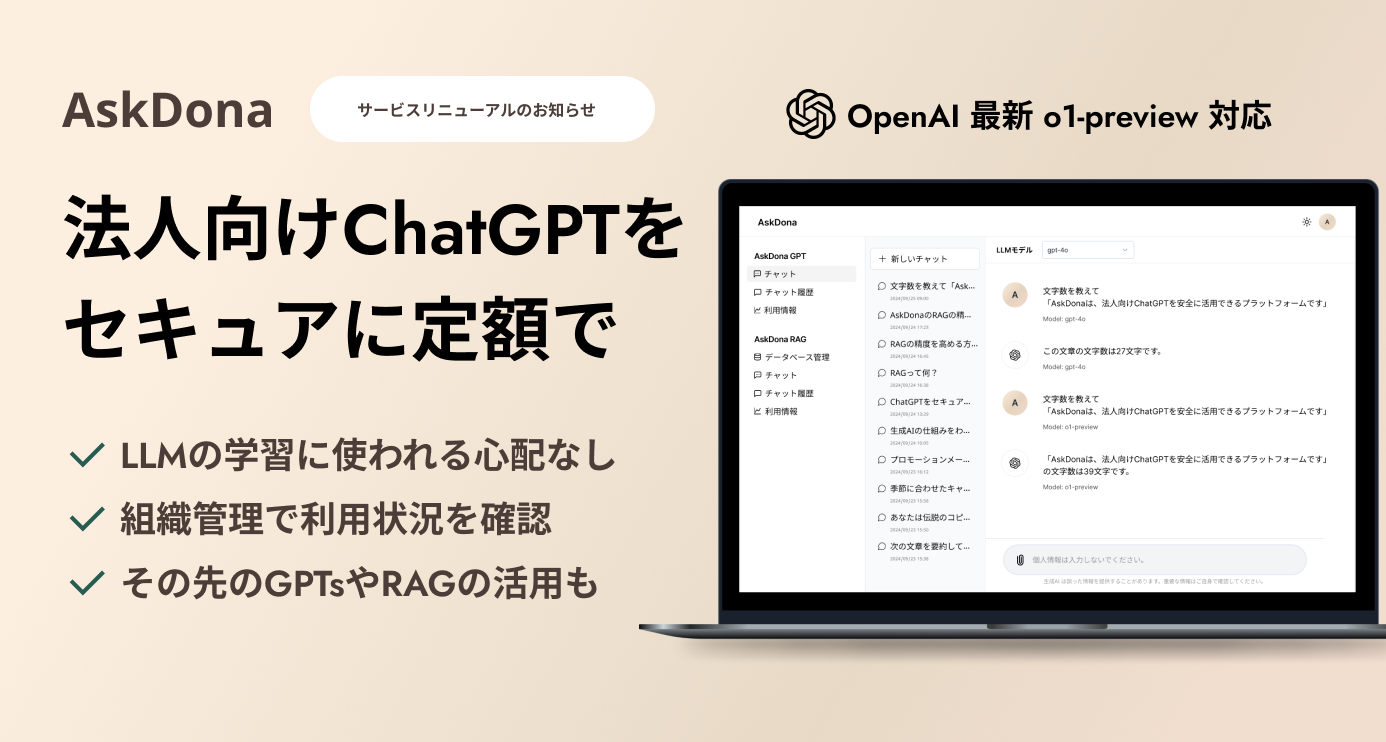
大規模言語モデルのトークンリミットとは? 2024.06.24 RAG Token 目次 0.0.1. トークンリミット(Token Limit)とは?0.0.2. トークンリミットの重要性0.0.3. トークンリミットを回避する方法0.0.4. 大規模言語モデル(LLM)のトークンリミット比較0.1. なぜ大規模言語モデルはトークンリミットを設定しているのか?1. トークンリミットを乗り越えることができるRAGとは?1.1. RAG(Retrieval-Augmented Generation)が必要な理由1.1.1. トークンリミットに依存しない回答生成1.1.2. 計算リソースの節約1.1.3. 回答の質の向上1.1.4. コスト管理1.1.5. ChatGPTを組織で活用ご興味ある方はお気軽にご連絡ください トークンリミット(Token Limit)とは? トークンリミットとは、LLMが一度に処理できるトークンの数に対する制限のことです。トークンは、単語やフレーズ、その他のテキストの一部を表す単位です。例えば、「I love you.」というフレーズは、「I」、「love」、「you」、「.」、「 」の5つのトークンで構成されます。 トークンリミットの重要性 トークンリミットは、LLMの性能に影響を与えるため重要です。トークンリミットが低すぎる場合、LLMは期待される出力を生成できない可能性があります。例えば、1000語のドキュメントを生成しようとしても、トークンリミットが1000であれば、最初の1000トークン分しか生成できません。 一方、トークンリミットが高すぎると、LLMの処理速度が遅くなり、高い計算能力が必要になります。 トークンリミットを回避する方法 トークンリミットを回避する方法はいくつかあります: 入力を小さなチャンクに分割する。 トークンカウンターを使用して、入力のトークン数を数える。 大規模言語モデル(LLM)のトークンリミット比較 以下に、主要なLLMとその能力の比較を示します: GPT-4 トークンリミット:32,768 推定語数:25,000語 特徴:複雑な推論と創造的なタスクに優れている。マルチモーダル入力(テキストと画像)をサポート。高い計算能力が必要で、速度は遅い。 価格:$20/月 トレーニングデータ:2021年9月 GPT-3.5 トークンリミット:4,096 推定語数:3,083語 特徴:単純な推論タスクや迅速な回答に適している。現実世界のデータを欠いている。 価格:無料 トレーニングデータ:2021年9月 Llama2 トークンリミット:2,048 推定語数:1,563語 特徴:自然言語処理と会話の理解に優れている。マルチモーダル入力(画像、テキスト、音声)をサポート。 価格:無料 トレーニングデータ:2022年9月 Claude 2 トークンリミット:100,000 推定語数:60,000語 特徴:複雑な論理タスクに優れているが、時々誤った情報を生成することがある。 価格:無料(米国と英国のみ) トレーニングデータ:2023年初頭 PaLM トークンリミット:8,000 推定語数:6,200語 特徴:特定の推論タスクでGPT-3を上回る。マルチモーダル入力(画像、テキスト、音声)をサポート。 価格:無料 トレーニングデータ:2021年中頃 なぜ大規模言語モデルはトークンリミットを設定しているのか? 計算リソースの節約大規模言語モデル(LLM)は、テキストを生成するために大量の計算リソースを必要とします。トークンリミットを設けることで、モデルが過度に多くのリソースを消費してクラッシュするのを防ぎます。 生成テキストの質の維持トークンリミットがあることで、生成されるテキストが過度に長くなり非現実的になるのを防ぎます。また、入力シーケンスが長すぎると、モデルが一貫性のあるテキストを生成するのが難しくなるため、トークンリミットは質の維持にも役立ちます。 コスト管理トークン数が増えると、その分だけ計算資源も多く必要になります。トークンリミットを設けることで、モデルの使用コストを抑えることができます。 アテンションメカニズムのスケーリングモデルの基盤となるアテンションメカニズムは、入力に対して二乗でスケールします。長い入力シーケンスでは、計算量が指数的に増加し、処理が非常に遅くなるため、トークンリミットが設けられています。 メモリ使用量の制限LLMは固定サイズのデータセットで訓練され、固定数のトークンを一度に処理するよう設計されています。この制限は、モデルがテキストを生成する際にメモリと計算資源を過度に消費しないようにするためです トークンリミットを乗り越えることができるRAGとは? RAG(Retrieval-Augmented Generation)が必要な理由 トークンリミットに依存しない回答生成 LLMはトークンリミットがあるため、一度に処理できるテキストの量が制限されています。RAGは、必要な情報を外部のデータソースから取得することで、入力シーケンスを短く保ちつつ、豊富な情報を提供できます。これにより、LLMがトークンリミットを超えることなく、詳細で正確な応答を生成することができます。 計算リソースの節約 トークンリミットを超える入力を処理しようとすると、計算リソースが大量に消費されます。RAGは、関連する情報を事前に取得してモデルに提供することで、モデルが直接大規模なテキストを処理する必要を減らし、計算資源の節約につながります。 回答の質の向上 LLMは、トークンリミットの制約内で一貫性のある高品質な応答を生成するのが難しい場合があります。RAGは、最新かつ関連性の高い情報を外部から取り入れることで、LLMの応答の質を向上させることができます。これにより、ユーザーはより正確で詳細な情報を得ることができます。 コスト管理 トークンリミットを超えてモデルを使用すると、計算コストが増加します。RAGは、効率的な情報取得と生成プロセスを通じて、モデルの使用コストを抑えることができます。 ChatGPTを組織で活用ご興味ある方はお気軽にご連絡ください 前の記事 RAGとは?LLMの回答の質を大幅に向上させるRAGの基本的なフローについて理解する 2024.06.22 次の記事 RAGとは?仕組みと導入メリット、導入時の事前知識や注意点をわかりやすく解説 2024.07.15