RAGとは?LLMの回答の質を大幅に向上させるRAGの基本的なフローについて理解する
- 2024.06.22
- RAG
近年、生成AIの技術革新が進み、大規模言語モデル(LLM)がさまざまな分野で活用されています。しかし、LLMにはいくつかの課題があり、その解決策として注目されているのがRAG(検索拡張生成)です。本記事では、RAGがなぜ必要なのか、その理由とメリットについて解説します。
RAGとは?
RAG(Retrieval-Augmented Generation)とは、大規模言語モデル(LLM)に外部情報を与えるための、ドキュメント検索(retrieval)と生成(generation)を組み合わせた技術です。RAGの目的は、特定の質問に対して関連するドキュメントから情報を引き出し、その情報を基に適切な回答を生成することです。
RAGの主要な要素
- ドキュメント検索(Retrieval):
- ドキュメントや情報源からテキストデータを抽出します。
- 抽出されたテキストを小さなチャンクに分割し、各チャンクをベクトル(埋め込み)に変換します。
- ベクトルストアに埋め込みを保存します。
- ユーザーの質問もベクトルに変換し、ベクトルストアから関連するチャンクを検索します。
- 生成(Generation):
- 検索された関連チャンクとユーザーの質問を結合してプロンプトを作成します。
- プロンプトを大規模言語モデル(LLM)に入力し、回答を生成します。
LLMの制限について
ChatGPTが今後どれだけ賢くなろうと、外部の知識や事実情報を必要とするタスクを行うには制限がつきまといます。言語モデルを訓練させるデータだけでなく、訓練データ以外の任意のデータから回答を生成できる場合にはるかに価値があり実務に活かせる状態になります。大規模言語モデルを一から再度訓練させるにはお金も時間もかかるためすでに存在するLLMに外部からのデータを与えるためのより良い方法が必要です。
プロンプトエンジニアリングという手法は一時的な解決策のみに利用できる可能性があります。LLMは、context window(コンテキストウィンドウ)として知られる限られた量のテキストのみを回答に考慮できます。GPT-3のモデルは、約12ページのテキスト(それは4,096トークンのコンテキスト)GPT-4 Turboは、約300ページのテキスト(それは128,000トークンのコンテキスト)までを見ることができます。確かに、コンテキストウィンドウが拡大することは、生成AIの性能を向上させる重要な要素です。コンテキストウィンドウが大きくなれば、モデルはより多くの情報を一度に処理し、文脈を深く理解することができます。しかし、コンテキストウィンドウの拡大だけでは解決できない問題も存在します。
LLMには、いくつか課題があります。
ハルシネーション(幻覚)の問題
LLMは膨大なデータから学習し、自然言語を生成する能力を持っていますが、時には事実に基づかない情報を生成する「ハルシネーション」が発生することがあります。これは、LLMが関連性の高い単語を推測して文を構築するためであり、信頼性の低い情報が混在するリスクがあります。
最新情報の欠如
LLMはトレーニングデータに基づいて学習されるため、最新の情報を常に反映することが難しいです。例えば、新しい法律や市場の動向などのリアルタイムな情報には対応しきれない場合があります。
専門性の欠如
LLMは一般的な情報には強いものの、特定の専門分野に関する知識には限界があります。これは、学習データが広範である一方、特定の領域に特化した情報が不足しているためです。
RAG(検索拡張生成)が必要な理由
検索拡張生成(Retrieval-Augmented Generation、RAG)は、大規模言語モデル(LLM)が回答を生成する過程に外部情報の検索を統合する手法です。この手法は、事前に訓練された知識ベースを超えた情報をデータベースから検索し、生成される回答の正確性と関連性を大幅に向上させます。
信頼性の向上
RAGは、LLMが生成するテキストに対して信頼性の高い外部情報を組み合わせることで、回答の精度と信頼性を向上させます。これにより、ハルシネーションのリスクを大幅に減少させることができます。
最新情報の利用
RAGを使用することで、最新のデータベースや情報ソースから必要な情報をリアルタイムで検索し、LLMに提供することができます。これにより、常に最新の情報に基づいた正確な回答を提供することが可能です。
専門的な知識の補完
RAGは、特定の専門分野に関するデータベースを参照することで、LLMの専門知識を補完します。これにより、特定の業界や分野においても高精度な回答を提供することができます。
RAG(Retrieval-Augmented Generation)とは?
RAG(Retrieval-Augmented Generation:検索拡張生成)とは、大規模言語モデル(LLM)によるテキスト生成プロセスに、外部情報の検索を組み合わせることで、回答の精度を向上させる技術です。「検索拡張生成」とも称され、この技術は、質問に対する回答を生成する際に、単にモデルが既に学習したデータベース内の情報のみに依存するのではなく、特定の知識や情報源への検索を組み合わせることにより、より専門的かつ正確な回答を提供することができます。これにより、生成された内容の正確性が格段に向上し、事実と異なる情報や文脈にそぐわない内容の生成を避けることが可能になります。RAGは、チャットボットや質問応答システム、コンテンツ作成ツールなど、多岐にわたる応用分野で有用性を発揮しています。
RAGのメリット:
- 最新情報の取り込み: RAGはリアルタイムで外部情報にアクセスし、最新の知識を反映させることができます。これにより、情報が常に更新され、ユーザーに最新のデータを提供することが可能です。
- 広範な知識ベース: 外部の知識ベースやデータベースにアクセスすることで、モデルはより広範囲の知識に基づいて回答を生成できます。これにより、特定のドメインに特化していないモデルでも、専門的な質問に対して正確な回答を提供できる可能性があります。
- カスタマイズ性: 特定のタスクやドメインに合わせて外部情報源を選択し、カスタマイズすることが可能です。これにより、特定の用途に合わせた回答生成が行えます。
RAGのデメリット:
- 外部情報への依存: 正確な回答生成のためには、外部情報源の質が重要になります。間違った情報や偏った情報源を使用すると、誤った回答を生成するリスクがあります。
- 計算コストとレイテンシ: 外部情報をリアルタイムで検索し、統合するプロセスは計算コストが高く、レイテンシが発生する可能性があります。これにより、応答速度が遅くなることがあります。
- 検索結果の統合の複雑性: 検索結果と生成モデルの出力を適切に統合することは技術的に複雑であり、精度の高い結果を得るためには慎重な設計と最適化が必要です。
RAGの技術についてステップを理解する
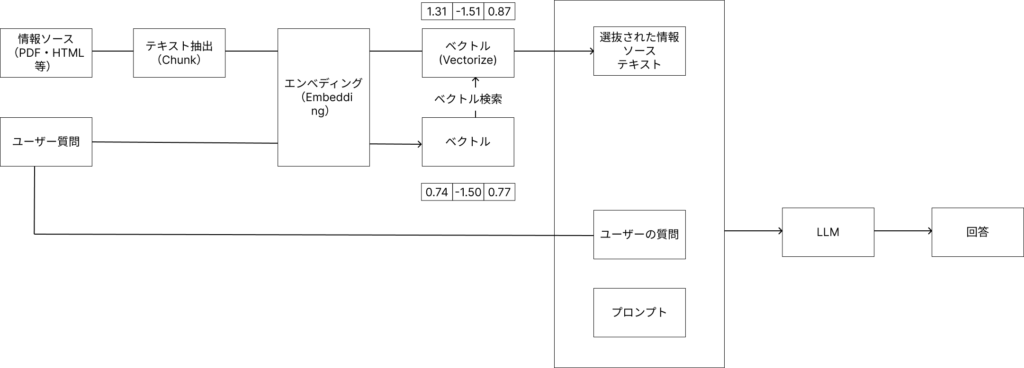
情報ソース(PDF・HTML等):
- PDFやHTML形式のドキュメントが入力されます。
- ドキュメントはテキストに変換されます。
テキスト抽出(Chunk):
- ドキュメントのテキストが抽出され、複数のチャンク(小さなセクション)に分割されます。
エンベディング(Embedding):
- 各チャンクはエンベディングモデルを使用してベクトルに変換されます。
ベクトル化(Vectorize):
- テキストとユーザーの質問がベクトルに変換されベクトルストアに保存されます。
ベクトル検索(Vector Search):
- ユーザーの質問に基づいて、ベクトルストアから関連するチャンクを検索します。
選抜された情報ソーステキスト:
- 検索された関連チャンクが選抜されます。
プロンプトの作成:
- 選抜された情報ソーステキストとユーザーの質問を結合してプロンプトを作成します。
LLM(Large Language Model)への問い合わせ:
- 作成されたプロンプトを元にLLM(大規模言語モデル)に問い合わせが行われます。
回答の生成:
- LLMが生成した回答がユーザーに提供されます。
-
前の記事

プロンプトチェーン(Prompt Chain)とは?プロンプトエンジニアリングの応用編 2024.06.21
-
次の記事
大規模言語モデルのトークンリミットとは? 2024.06.24