9月12日最新:OpenAI社の大規模言語モデル「o1」にも適用されたChain-of-Thought (CoT)とは?
- 2024.09.13
- ChatGPT
OpenAI社の大規模言語モデル「o1」とは?
2024年9月、OpenAIは新しい大規模言語モデル「o1」を発表しました。reinforcement learningによって訓練されたo1は、複雑な推論タスクに特化して設計されており、競技プログラミングや学術ベンチマークにおいて、従来のモデルを凌駕するパフォーマンスを発揮します。
- o1は「Chain-of-Thought」アプローチを採用。回答前に段階的に思考することで推論能力を向上させています。物理学、生物学、化学の問題解決において特に目覚ましい改善を見せており、人間のPhDレベルの精度すら超えています。
- OpenAI o1モデルは、Chain-of-Thoughtプロセスを活用することで、複雑な推論や学術タスクに秀でています。とはいえ、より幅広いユーザーが使いやすくするため、現在も改良が続けられています。
- o1は競技プログラミングのCodeforcesで上位89パーセンタイルにランクイン。USA Math Olympiad(AIME)では上位500人の学生に匹敵する成績を収め、物理学、生物学、化学のGPQAベンチマークでは人間のPhDレベルの精度を上回っています。さらに、テスト時の計算リソースを増やすことで、パフォーマンスも向上します。
- AIMEのような数学ベンチマークにおいて、o1はコンセンサス再ランキングによって93%の精度を達成。GPT-4o(12%)を大きく引き離し、人間の専門家にも匹敵する実力を示しました。また、57個あるMMLUサブカテゴリのうち54個でpass@1精度が向上。推論負荷の高いタスクでは、より長いChain-of-Thoughtが結果を改善することが実証されました。
- o1モデルは現在、「o1-preview」という早期リリース版として提供されており、ChatGPTおよび信頼できるAPIユーザーがアクセス可能です。より使いやすいモデルを目指して、現在も改良作業が進められています。
Chain-of-Thought (CoT)とは?
人間の推論と同じように、Chain of Thought(チェーンオブソーツ), CoTは、論理的な推論を段階的に進めることで、複雑な問題を体系的に解決するのに役立ちます。元々プロンプトエンジニアリングのテクニックの手法として認知されていましたが、今回OpenAIがo1のLLMモデルに組み込んだという点は大きくLLMの性能や能力を向上ささせたことを意味します。
人工知能(AI)において、Chain of Thoughtは、人間のような推論プロセスを再現する手法です。これは、複雑な問題を複数の論理的なステップに分解し、最終的な解決策へと導きます。この手法は、人間の知性の本質的な側面を反映し、構造化された問題解決のためのメカニズムを提供します。言い換えれば、CoTは、複雑な問題を理解しやすい中間的な思考に分解し、それらを順番に組み合わせて最終的な答えにたどり着く認知戦略に基づいています。
Chain-of-Thought (CoT) Promptingとは?
Chain-of-Thought (CoT) Promptingは、Weiらによって2022年に導入された技術で、複雑な推論能力を向上させるための手法です。この手法は、自然言語処理(NLP)モデルが問題を解決する際に、中間的な推論ステップを明示的に示すことで、より正確で信頼性の高い回答を生成することを目的としています。
参考文献:Wei et al. (2022), “Chain-of-Thought Prompting”
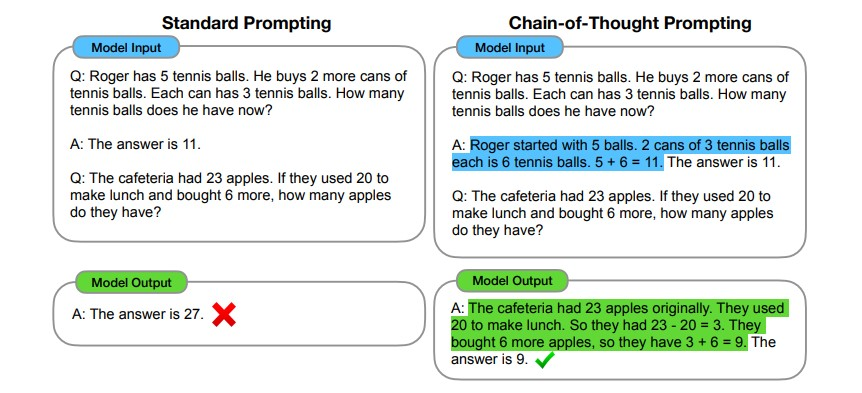
CoTの要点:
- 複雑な推論: LLM(大規模言語モデル)に複雑な推論を行わせることができます。
- 段階的思考: 問題を一度に解くのではなく、一歩ずつ段階的に考えさせます。
- 解釈可能性: モデルがどのように答えに至ったかを、ステップごとに追跡できます。
- Few-shot プロンプティングとの組み合わせ: 複雑なタスクでより良い結果を得るために、Few-shot プロンプティングと組み合わせることができます。
- 大規模モデルでの効果: 十分に大きな言語モデルで現れる能力とされています。
- 実装方法: プロンプトの最後に “Let’s think step by step” (ステップごとに考えてみましょう) という文を追加するだけで実装できます。
CoTの能力を発揮できるLLMとは?
CoT(Chain-of-Thought)推論は、1000億パラメータを超えるモデルのスケーリングによって現れるLLM(大規模言語モデル)の新たな能力です。小規模なLLMではパフォーマンスにプラスの影響を与えず、このサイズのモデルで使用した場合にのみパフォーマンス向上が見られます。その理由は二つあります。
まず、小規模なLLMは流暢で論理的な長い思考の連鎖を生成することができません。これにより、標準的なプロンプティングよりも低いパフォーマンスになります。次に、CoT推論はより複雑な問題に対して効果的です。問題を解決するために必要な主要なステップを特定し、その後解決に至る思考の連鎖を生成する能力がLLMに求められます。小規模なLLMは、大規模なLLMほどこれを効果的に行うことができないかもしれません。
CoT推論が大規模LLMで現れるもう一つの理由は、事前学習データにも依存するといわれています。大規模なLLMは通常、ステップバイステップの推論を含む巨大なデータセットで訓練されており、これが思考の連鎖的な推論能力の発展を助ける可能性があります。指示に従う能力はCoTの能力に必ずしも必要ではないようで、指示に従うようにファインチューニングされていないLLMでもゼロショットや少数ショットのCoT推論が示されました。しかし、指示に従うことはCoT推論の質を向上させる可能性があります。
CoT vs. 一般的なプロンプトエンジニアリングどっちがいいの?
一般的なプロンプトエンジニアリングは、入力と出力のペアを例として使用します。これらのペアは質問と回答として認識されます。モデルはこれらのペアに基づいて回答を予測します。マルチステップの推論タスクを効果的に処理することには限界がありますが、単一ターンの質問のような単純なタスクには適しています。必要な計算リソースは少なくて済みます。
一方、CoTプロンプトは中間の推論ステップが最終的な回答を提供する前に行われます。CoTプロンプトは複雑な推論に優れており、モデルがステップバイステップで考えることを可能にします。多様なタスクに適用可能で、複雑な推論を必要とするタスクに適しています。プロンプトのシーケンスでトレーニングを行い、マルチステップの推論にデータを効率的に利用します。大規模なモデルで性能が向上し、そのためにより多くの計算力が必要です。複雑な推論ベンチマークやマルチステップの問題解決を要求するタスクにおいて優れた性能を発揮します。
Tree of Thoughts(ToT)とChain of Thought(CoT)何が違うの?
Tree of Thoughts(ToT)は、Chain of Thought(CoT)プロンプトを一般化し、複雑な問題解決において探索や戦略的な見通しを促進するフレームワークです。ToTは、CoTの「一連の中間ステップ」という概念をさらに拡張し、ツリー構造で思考を保持します。これにより、複数の選択肢や経路を同時に探索し、最適な解決策を見つけることが可能になります。このアプローチにより、言語モデル(LM)は問題解決に向けた進捗を中間思考を通じて自己評価することができます。Chain of Thought(CoT)の基本概念CoTプロンプトは、問題解決の過程を一連の中間ステップに分解し、各ステップを順番に解決していくアプローチです。これにより、モデルは複雑な問題を段階的に解決することができます。例えば、数学の問題を解く際に、問題を小さな部分に分けて一つずつ解決する方法です。
ToTは、思考の生成と評価を検索アルゴリズム(例:幅優先探索や深さ優先探索)と組み合わせて、見通しとバックトラッキングを伴う体系的な思考の探索を可能にします。これにより、LMは複雑な問題に対して段階的かつ戦略的にアプローチすることができ、より高い精度で問題を解決することができます。
ToTの主な利点は、複雑な推論や問題解決タスクにおいて、LMが複数の関連するアイデアを同時に追跡し、長いテキストの一貫性を維持する能力を持つことです。これにより、ToTはCoTに比べて計算資源を多く必要としますが、より高度な問題解決能力を提供します。
Tree of Thoughts(ToT)の具体例を示すために、複雑な問題解決のシナリオを考えてみましょう。例えば、「ある都市の最短経路を見つける」という問題を解決する場合を考えます。
問題設定
「A地点からB地点までの最短経路を見つける」という問題を解決するために、ToTを使用します。
ToTの適用例
- 初期状態の設定:
- 出発点:A地点
- 目的地:B地点
- 現在の経路:A
- 思考の生成:
- A地点から行ける次の地点を考える(例:C地点、D地点)。
- それぞれの地点に対して、次のステップを考える。
- ツリー構造の形成:
- A → C
- A → D
- 中間ステップの評価:
- A → C の場合、C地点からさらに行ける地点を考える(例:E地点、F地点)。
- A → D の場合、D地点からさらに行ける地点を考える(例:G地点、H地点)。
- ツリーの拡張:
- A → C → E
- A → C → F
- A → D → G
- A → D → H
- 評価とバックトラッキング:
- 各経路の距離を評価し、最短経路を見つける。
- 例えば、A → C → E → B が最短経路であると判断された場合、その経路を選択。
最終的な解決策
ToTを使用することで、A地点からB地点までの最短経路を段階的に探索し、最終的に最適な経路を見つけることができます。このプロセスでは、各ステップで複数の選択肢を評価し、最適な経路を選択するための戦略的な見通しを持つことが重要です。
このように、ToTは複雑な問題解決において、段階的かつ体系的なアプローチを提供し、より高い精度で問題を解決することができます。
LLMが計算に弱い?「数学的な計算問題が苦手」の真実
近年、多くのニュースで「LLMに計算問題を解かせてみたけど解答が間違っている」という記載の内容のブログを見ますが、LLM(大規模言語モデル)が計算に弱いとされる理由は、実際にはモデル自体の性能だけでなく、プロンプトエンジニアリングの質にも大きく依存しています。LLMは基本的にテキストデータを基に学習しているため、数値計算の精度や効率性は専用の数値計算アルゴリズムに比べて劣ることがあります。特に、複雑な数式や高精度の数値計算が必要な場合、LLMはそのタスクを正確に遂行するのが難しいことがあります。また、LLMは大量のテキストデータを基にトレーニングされていますが、その中には数値計算に特化したデータが少ないことが多く、数値計算に関する知識やスキルが十分に学習されていない場合があります。
しかし、LLMの性能は与えられるプロンプトの質に大きく依存します。適切なプロンプトを設計することで、モデルが持つ潜在的な能力を最大限に引き出すことができます。例えば、計算タスクに対しては、明確で具体的な指示を含むプロンプトを提供することで、モデルの回答精度を向上させることができます。また、CoT(Chain of Thought)プロンプトのように、中間の推論ステップを導入することで、複雑な計算タスクを段階的に解決することが可能になります。これにより、モデルが一度に全ての計算を行うのではなく、ステップバイステップで問題を解決することができ、結果として精度が向上します。さらに、プロンプトエンジニアリングでは、モデルの出力に基づいてプロンプトを調整するフィードバックループを活用することが重要です。これにより、モデルの回答の質を継続的に改善することができます。
したがって、LLMが計算に弱いとされるのは、モデル自体の限界だけでなく、プロンプトエンジニアリングの質にも大きく依存しています。適切なプロンプト設計や中間ステップの導入、フィードバックループの活用などを通じて、LLMの計算能力を最大限に引き出すことが可能です。LLMの計算能力を評価する際には、プロンプトエンジニアリングの重要性を理解し、それを適切に活用することが不可欠です。
-
前の記事

法人が活用できるChatGPTのビジネスプロンプト200選!プロンプトを使いこなして業務効率化! 2024.09.12
-
次の記事
The Intelligence Age 知能の時代 2024.09.24