RAGの一部に使われる、文脈内学習(In-Context Learning)とは?
- 2024.05.27
- RAG
In-Context Learning(ICL)文脈内学習とは?
In-Context Learning(ICL)文脈内学習は、事前に訓練された大規模言語モデル(LLM)が、モデルを微調整することなく新しいタスクに対応できるようにする技術です。この手法では、タスクのデモンストレーションを自然言語形式でプロンプトに統合し、LLMに入力します。LLMは、入力されたプロンプトからタスクの文脈を理解し、適切な回答や出力を生成します。
In-Context Learningは、教師あり学習とは異なり、モデルのパラメータを更新することなく、事前に学習した知識を活用して新しいタスクに迅速に適応します。このプロセスでは、モデルが提供された情報から潜在的なパターンを識別し、それに基づいて予測を行います。
また、In-Context LearningはFew-Shot Learningや few-shotプロンプティングとも呼ばれ、多数の学習データや長期間の訓練プロセスを必要とせずに、限られたfew-shotサンプルや例示から新しいタスクや問題を理解し、適切な反応や解答を生成できる能力を指します。この方法で得られる知識は一時的であり、推論後にLLMが情報を持続的に蓄積することはありません。これにより、モデルのパラメータの安定性が保たれます。
文脈内学習(ICL)の効果は、LLMが持つ広範な事前訓練データと大規模なモデルスケールを活用する能力に起因しています。これにより、LLMは従来の機械学習アーキテクチャの学習プロセスを必要とせずに、新しいタスクを理解し実行できます。
この文脈での「広範な事前訓練データ」とは、LLMが訓練される際に用いられる膨大なテキストデータのことを指し、このデータには多様な言語パターン、知識、文脈が含まれています。LLMはこのデータから言語の構造、文脈の理解、知識の抽出など、言語に関する複雑なタスクを実行するための能力を学習します。
また、「大規模なモデルスケール」とは、LLMが持つ膨大なパラメータ数を指し、これによりモデルは高度な言語理解と生成能力を実現します。大規模なモデルは、より多くの情報を記憶し、より複雑な言語パターンを認識する能力を持っています。
In-Context Learning(ICL)文脈内学習が必要な理由とは?
文脈内学習(ICL)が重視される理由は、人間が新しいことを学ぶ時のように、大規模言語モデル(LLM)も外部から与えられた情報からより能力を最大限に発揮することができるからです。
ICLのアプローチは、人間の認知的推論プロセスを反映しており、問題解決のためのより直感的なモデルとなっています。これは、人間が新しい問題に直面したときに、過去の経験や既存の知識から関連する情報を引き出し、それを基に解決策を導き出すプロセスに似ています。私たち人間が新しい問題に直面した時、過去の経験からヒントを得て解決策を考えます。ICLはその人間の思考プロセスを模倣し、LLMに少数の例から多くを学ばせることができます。つまり、部から与えられた情報を通して、LLMは新しいタスクを理解し、解決策を提案できるようになります。
従来の方法では、新しいタスクごとにモデルを一から訓練し直す必要がありましたが、ICLを使うと、その必要がなくなります。これにより、時間やコストを大幅に削減し、より迅速に新しいタスクに対応できるようになります。ICLは計算コストが低く、実際のビジネスやサービスでの導入がしやすくなります。つまり、言語モデルをさまざまなシナリオで活用しやすくなるということです。
さらに、ICLは、より広範なラベル付きデータセットで訓練されたモデルと比較しても、様々な自然言語処理(NLP)ベンチマークで競争力のある高パフォーマンスが評価されています。たとえ外部情報が少なくても、ICLを用いたLLMは、大量のデータで訓練されたモデルと同等、またはそれ以上の成果を出すことができます。これは、LLMがもともと持っている膨大なデータからの学習が生かされるためです。
In-Context Learning(ICL)文脈内学習ってどういう技術?
文脈内学習が大規模言語モデル(LLM)でどのように機能するかというと、その核心は「類推から学ぶ(類推思考)」※アナロジー思考とも呼ばれ、2つ以上の物事の間にある共通点に着目し、考えている課題に応用する思考法という原理にあります。この原理により、モデルは少数の入出力例、場合によっては1つの例から一般化する能力を持ちます。このアプローチでは、タスクの説明や一連の例が自然言語で形成され、モデルに「プロンプト」として提示されます。このプロンプトはsemantic prior(意味的事前知識)として機能し、モデルの思考の流れやその後の出力を導きます。従来の機械学習手法(例えば線形回帰)がラベル付きデータと別個の訓練プロセスを必要とするのに対し、文脈内学習は事前訓練されたモデル上で動作し、パラメータの更新を伴いません。
文脈内学習の効果は、pre-trainingフェーズとモデルパラメータのスケールに密接に関連しています。研究によると、モデルのパラメータの数が増えるにつれて、文脈内学習を行う能力が向上します。事前訓練中には、モデルは訓練データから幅広いsemantic priorを獲得し、これが後にタスク固有の学習表現の助けとなります。この事前訓練データが、文脈内学習の基盤となり、モデルが追加の入力を最小限に抑えつつ複雑なタスクを実行できるようにします。
文脈内学習は、Few-Shot Learningのシナリオで頻繁に用いられます。Few-Shot Learningにおいて効果的なプロンプトを作成する技術は、「プロンプトエンジニアリング」と呼ばれ、モデルの文脈内学習能力を活用する上で重要な役割を果たします。
要するに、文脈内学習は、モデルが過去に蓄積した知識を基に、新しい問題に対して直感的に反応できるようにする手法です。これにより、LLMは少ない情報からでも幅広いタスクに柔軟に適応することが可能になります。
In-Context Learning(ICL)の技術的手法とは?
Few-Shot Learning
モデルは複数の入出力ペアを例として使用してタスクの説明を理解します。これらの例はセマンティックプライオリ(semantic prior)として機能し、モデルが新しいタスクを一般化して実行するのを可能にします。このアプローチは、モデルの事前訓練データ(pre-training data)と既存のモデルパラメータを活用して、複雑なタスクに対する正確な次のトークン予測を行います。
One-Shot Learning
文脈内学習のより制約された形態で、モデルはタスクを理解するために1つの入出力例のみを与えられます。限られたデータにもかかわらず、モデルは事前訓練されたパラメータとセマンティックプライオリを利用して、タスクの説明に沿った出力を生成します。この方法は、ドメイン固有のデータが少ない場合によく使用されます。
Zero-Shot Learning
モデルにタスク固有の例は提供されません。代わりに、タスクの説明と既存の訓練データのみに依存して、要件を推論します。このアプローチは、モデルが事前訓練フェーズから新しい、未遭遇のタスクへと一般化する固有の能力を試します。
In-Context Learning(ICL)の種類とは?
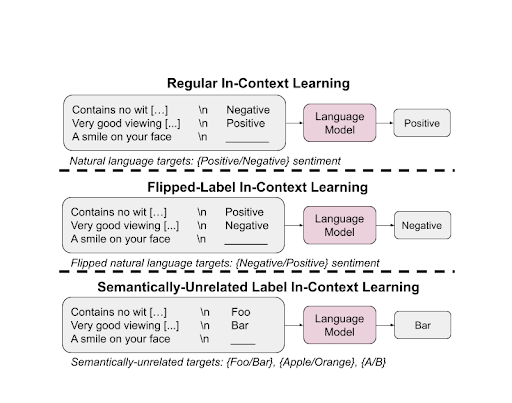
通常のICL(Regular ICL)
通常の文脈内学習(Regular In-Context Learning; ICL)は、タスク固有の学習アプローチの基盤となります。モデルは、事前訓練フェーズで獲得したセマンティックプライオリ(semantic prior)の知識を利用して、文脈内の例の形式に基づいてラベルを予測します。例えば、タスクが感情分析を含む場合、モデルは「ポジティブな感情」と「ネガティブな感情」に関する事前訓練された理解を活用して適切なラベルを生成します。
フリップドラベルICL(Flipped-Label ICL)
フリップドラベルICLは、文脈内の例のラベルを反転させることで複雑さを導入します。これにより、モデルはセマンティックプライオリを覆すことを強いられ、入力ラベルのマッピングに従う能力が試されます。この設定では、大きなモデルは事前訓練されたセマンティックプライオリを覆すことができる能力を持ちますが、小さなモデルではこの能力が観察されません。
意味的に無関係なラベルICL(Semantically-Unrelated Label ICL; SUL-ICL)
SUL-ICLは、文脈内の例のラベルを意味的に無関係な用語に置き換えることで異なるアプローチを採ります。これにより、モデルはセマンティックプライオリに頼ることなく、入力ラベルのマッピングを一から学ぶように指示されます。大きなモデルはこの形式の学習により適しており、事前訓練されたセマンティック知識にのみ依存せずに新しいタスクの説明に適応できる能力を示しています。
指示チューニング(instruction tuning)は、モデルが入力ラベルのマッピングを学ぶ能力を高める一方で、セマンティックプライオリへの依存を強化します。この二重の効果は、指示チューニングがICLパフォーマンスを最適化するための重要なツールであることを示唆しています。
In-Context Learning(ICL)のユースケースや実用性とは?
文脈内学習(ICL)は、大規模言語モデル(LLMs)に革新的なアプローチをもたらし、明示的な再訓練なしに新しいタスクへの適応を可能にしました。ICLの実世界での応用範囲は広大であり、様々なセクターにわたってこの学習パラダイムの多用性と潜在性を示しています。以下は、ICLが大きな影響を与えている、または与える可能性がある5つの主要な応用例です:
感情分析
ICLの力を活用して、LLMsに少数の例文とその感情(ポジティブまたはネガティブ)を与えることができます。新しい文が提示されると、モデルは明示的な訓練なしにその感情を正確に判断できます。この能力は、顧客フィードバック分析、市場調査、ソーシャルメディアのモニタリングを革命的に変える可能性があります。
カスタマイズされたタスク学習
従来の機械学習モデルでは、新しいタスクごとに新しいデータで再訓練する必要があります。しかし、ICLを使えば、LLMsは少数の例を見せるだけでタスクを実行する方法を学べます。これは、必要な時間と計算リソースを大幅に削減し、産業が迅速に変化する要件に適応できるようにします。
言語翻訳
異なる言語の文の入出力ペアをいくつか提供することで、モデルに新しい文を翻訳させることができ、グローバルビジネスにおけるコミュニケーションの障壁を解消します。
コード生成
コーディング問題とその解決策の例をいくつかモデルに与えることで、新しい、類似の問題に対するコードを生成できます。これにより、ソフトウェア開発プロセスが加速され、手動コーディングの労力が削減されます。
医療診断
ICLは、医療症状とそれに対応する診断の例をいくつか示すことで診断目的に利用できます。新しいケースを診断するようにモデルに促すことで、医療専門家が情報に基づいた判断を下し、患者にタイムリーなケアを提供するのに役立ちます。
In-Context Learning(ICL)の課題や制限とは?
モデルパラメータとスケール
ICLの効率はモデルのスケールに密接に関連しています。小さなモデルは、大きなモデルとは異なる文脈内学習の能力を示します。
訓練データ依存
ICLの有効性は、訓練データの品質と多様性に依存します。不十分または偏った訓練データは、最適でないパフォーマンスにつながる可能性があります。
ドメイン特異性
LLMsはさまざまなタスクを一般化できますが、高度に特殊化されたドメインを扱う際には制限があります。最適な結果を達成するためには、ドメイン固有のデータが必要になる場合があります。
モデルファインチューニング
ICLを使用しても、特定のタスクに対応するためや望ましくない新たな能力を修正するために、モデルファインチューニングが必要になるシナリオが存在するかもしれません。
ICLの研究領域は急速に進化しており、GPT-4などの大規模言語モデルが文脈内学習をどのように活用しているかについての最近の進歩が示されています。研究者は、ICLを引き起こす根底にあるメカニズム、訓練データ、プロンプト、またはアーキテクチャの微妙な違いを探求しています。ICLの未来は有望ですが、まだ多くの未解決の質問や克服すべき課題があります。
倫理と公正
動的な学習環境では、モデルが訓練データから学んだ偏見や不平等を継続する固有のリスクがあります。特に文脈が絶えず進化する場合に、人工知能が倫理的かつ公正に機能することを保証することは、難しい課題です。
-
前の記事

LLMのファインチューニングとは?:基本から応用まで徹底解説 2024.05.26
-
次の記事
プロンプトエンジニアリングとは?事例とユースケースの解説 2024.05.27